Malware Detection
Yu-Chieh Chen, Ruoyu Liu, Yikai Hao
Overview
As the technology grows fast in recent years, more and more people cannot live without cell phones. It is important to protect users’ data for cell phone companies and operating system providers. Therefore, detecting malwares based on the code they have can avoid publishing of malwares and prohibiting them from the source. This report aims at finding a model which can detect malwares accurately and with a small computational cost. It uses different matrices and graphs to search the relationships between applications and detecting malwares based on the similarity. As a result, the best model can achieve a test accuracy around 99%.
Data Overview
Data Description
The data source is called Android Malware Dataset (AMD). The dataset is published in 2017 by the Argus Lab from the University of South Florida. This data source is used by many other malware detection papers and widely used in the research domain. We then extract the smali file after decompiling the APK(Android Application Package).
Smali
In order to analyze the smali files, we should understand the structure of it. Therefore, here is the description of the smali files and the features contained in the smali files.

API Call
In order to understand which part of the smali files do the malicious action, we put our attention on API (Application Programming Interface) calls. There are four main components in an API call.

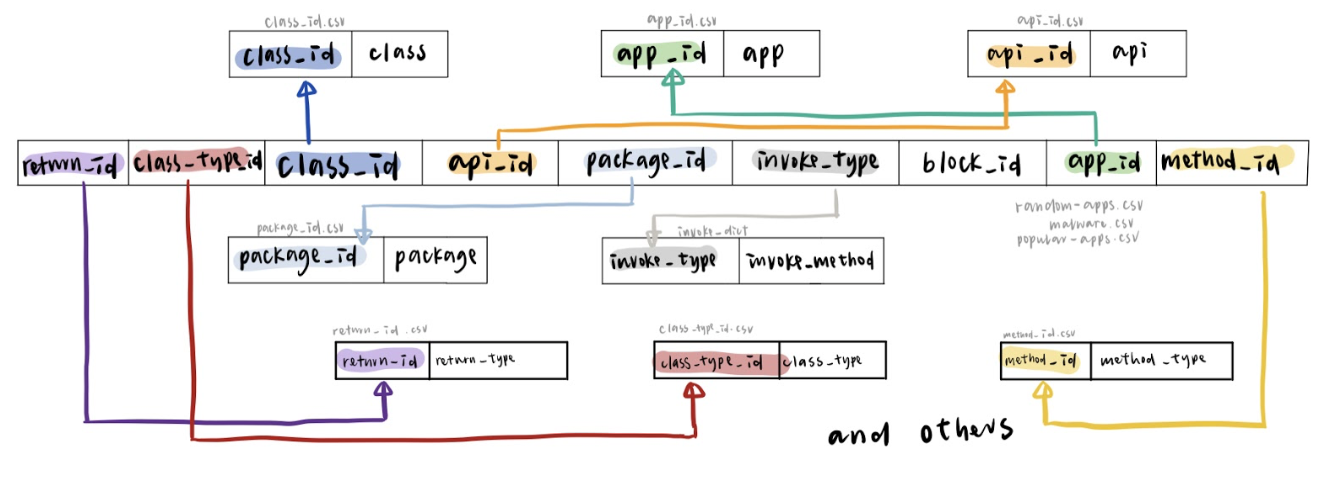
Database
We design a new database for storing data.
Data Statistics
After picking out the features we want, we do some simple analysis based on the data we have. As the table shows, the size difference between malwares and benigns are huge. In addition, the unique api calls in benigns are about 10 times larger than malwares. Therefore, the difference between malwares and benigns do exists and we are able to find some way to detect malwares.
| Type | API called once (sum/app) | Number of API | Number of Class | Number of Application |
|---|---|---|---|---|
| Malware | 29.05 | 792.08 | 284.32 | 905 |
| Popular | 689.09 | 8214.12 | 3930.60 | 324 |
| Random | 340.34 | 6387.03 | 2893.34 | 581 |
Model
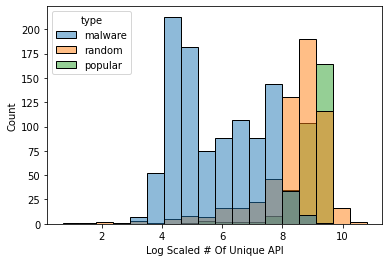
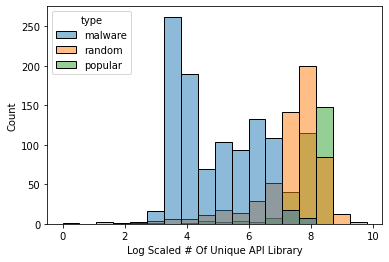
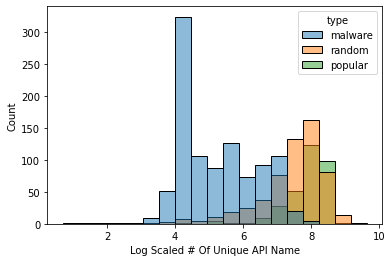
Feature Distribution
After picking out the features we want, we do some simple analysis based on the data we have. As the table shows, the size difference between malwares and benigns are huge. In addition, the unique api calls in benigns are about 10 times larger than malwares. Therefore, the difference between malwares and benigns do exists and we are able to find some way to detect malwares.
| Type | #Unique API | #Unique API Lib | #Unique API Name | #Unique API Return Type/th> |
|---|---|---|---|---|
| Malware | 792.08 | 277.34 | 359.55 | 172.18 |
| Benign | 7041.15 | 2551.21 | 2571.26 | 1485.79 |
As we can see from the graphs, the distribution of every application type for every feature is different.
| # of Unique API Call | # of Unique API Lib |
|---|---|
 |
 |
| # of Unique API Name | # of Unique API Return Type |
 |
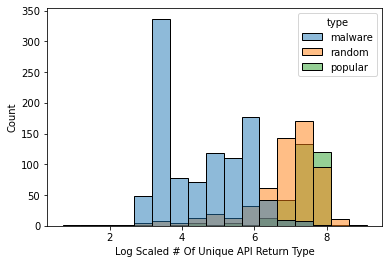 |
Hindroid
HinDroid is the baseline model we use for our report. It contains different types of kernels and the meaning behind each kernel is different. It uses the features we extract from the data generating process to build some matrices. Each matrix shows a type of relationship between apis or applications. Each matrix is an adjacent matrix for a graph with a specialized relationship. By choosing different types of matrices we want to combine together, we get the kernel we have. Then we will be able to use the custom kernels and put in different classifiers like SVM or Random Forest for malware detection.
The four types of matrices are: A, B, P, and I matrices.
- A matrix shows the connection among apis and applications. The value within the A matrix will be one if the application contains the api.
- B matrix shows the connection between apis. The value within the B matrix shows whether two apis are contained in the same code block.
- P matrix also shows the connection between apis. The value within the P matrix shows whether two apis use the same package.
- I matrix shows the connection within the apis. The value within the I matrix shows whether two apis use the same invoke type.
Currently, due to the large size of the unique apis we get, we are not able to calculate out the I matrix yet. Therefore, the kernel we have now for HinDroid is AA, ABA, APA, and APBPA. Some logic of example kernels are shown below.
New Model
The HinDroid model runs pretty slow since there are a large number of APIs. However, lots of APIs only appear once among all applications and they are meaningless for detecting malwares. In addition, there are also some APIs which appeared in almost every application. Those APIs are also not meaningful enough to help us pick out the malwares. Therefore, new models are being considered and built. Based on the logic of HinDroid, we try to develop some new matrices to replace the original matrices which will have a faster speed and similar accuracy.
Reduce API/Pack
The inspiration of this method comes from the MAMADROID. Instead of using the whole API call, API name and API library have been selected separately. The number of unique API calls for around 2000 applications are originally over 1,000,000. We design two new matrices based on the separation of values in an API call.

- Reduce API: This matrix only contains the API Name, which is the red part in the example. The new matrix size is around 130,000 x 130,000, which is way smaller than the original A matrix.
- Reduce Pack: This matrix only contains the API Library, which is the blue part in the example. The new matrix size is around 350,000 x 350,000. The size is about 2/3 smaller than the original A matrix.
TF-IDF
Besides Reduce API and Reduce Pack, we are also considering can we select out some APIs which are considered “important” for detecting malwares. The method we choose is TF-IDF(term frequency - inverse document frequency). It is a useful method to check the importance of a word for a document. We generate a corpus list which each element in the list is representing a corpus for an application. In each corpus, it contains all API calls. We then use the TF-IDF to get a token score for each API call. After calculating the mean score over all corpus, part of the API calls are selected out according to their rank. The numbers we select out are Top1000, Top2000, Top5000, and Top10000.
| Top3 API Example Rank by TF-IDF |
|---|
| Ljava/lang/StringBuilder;-> append() |
| Ljava/lang/StringBuilder;-> toString() |
| Ljava/lang/Integer;->valueOf() |
New Features
New features are also being considered to build new matrices.
We use the return type as our new feature and build a matrix called R.
The element in the R matrix represents whether two applications are using the same return type.
R matrix can replace the original A matrix and its size is only around 170,000 x 170,000.
As the feature description part shown, the return type is also a useful feature to detect malwares.
Additionally, in order to build a new kernel for the R matrix, the new B_R matrix represents whether two return types are in the same code block.
Therefore, we have two different kernels - RR and RB_RR.
What’s more, we also built a new I matrix after finishing the API reduction.
This also provides more kernel options while putting the features into classifiers.
Word2Vec
Word2Vec is the new vector embedding we generate.
This model is a powerful NLP model to help us find not only the direct relationship between apps but also the cluster connection between apps using the graph,
which is a different approach to solve the malware detection problem with HinDroid.
Our Word2Vec takes AA as an input and builds a graph based on the AA. Therefore, the graph contains two components - applications and apis. We then generate sentences as our input for the Word2Vec model. Firstly, we randomly pick an app out, then we follow the path in the graph to search for the next api and app. We will end our path with an app. The length of the path will be a number randomly chosen within the range of maximum length.
For example, with a maximum length of 5000 and a metapath AA, the possible text generated will be like:
APP1 -> API234 -> APP34 -> API12 -> APP78 -> …
After finishing the sentence generating process, we will implement the genism’s Word2vec model to get our vector embeddings for every application and api. The final vector embeddings will be easily used in different machine learning models.
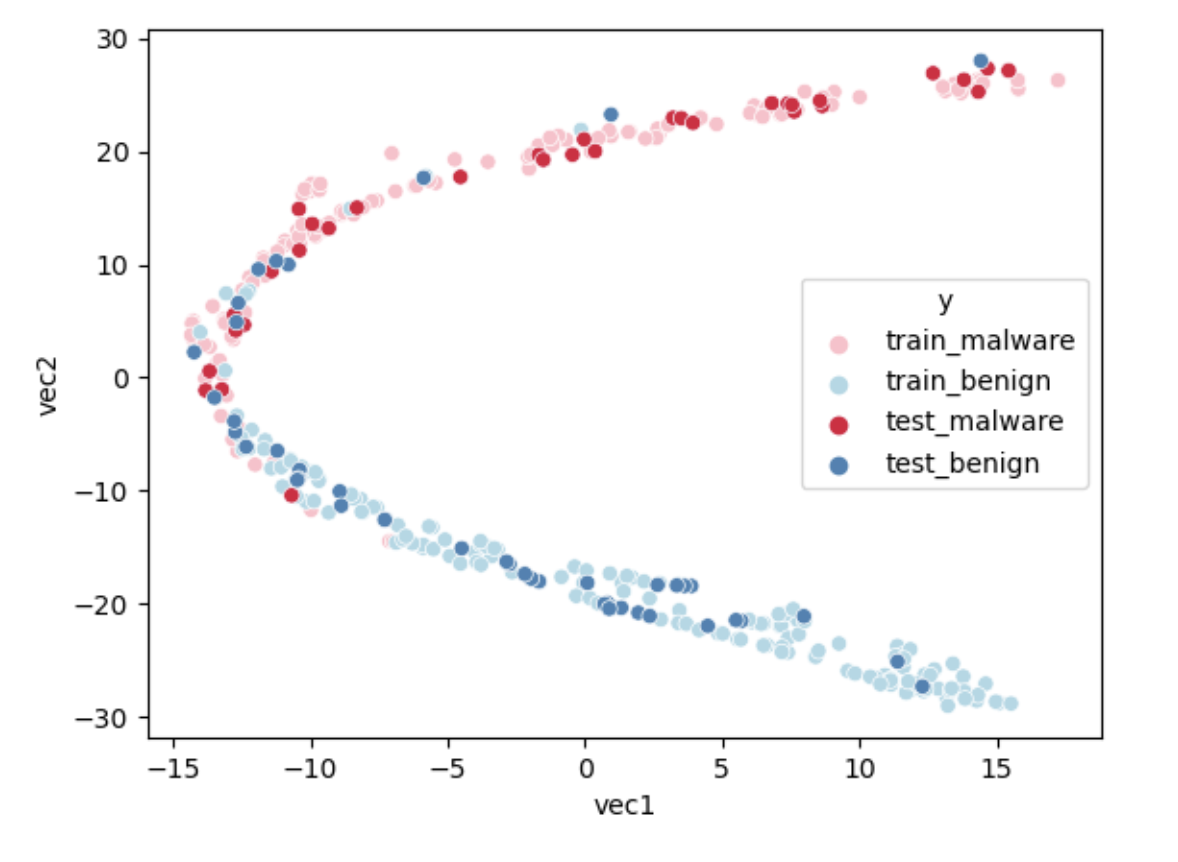
We use data visualization to check if our model makes sense. Our plot shows the vector embeddings after the dimension reduction using a method called t-SNE(t-distributed stochastic neighbor embedding). This method can project a high dimensional vector into a two dimensional space. t-SNE uses Barnes-Huts approximations to reduce the dimensions. As the graph shown below, the distribution of malwares and benigns are separated. Benigns are condensed at the left side with small x and y values. However, malwares are distributed at the right side, with a large x value and widespread y value. From the information on the graph, the model can detect malwares well. Although a few points are mixed in the graph, they might be separable in higher dimensions.
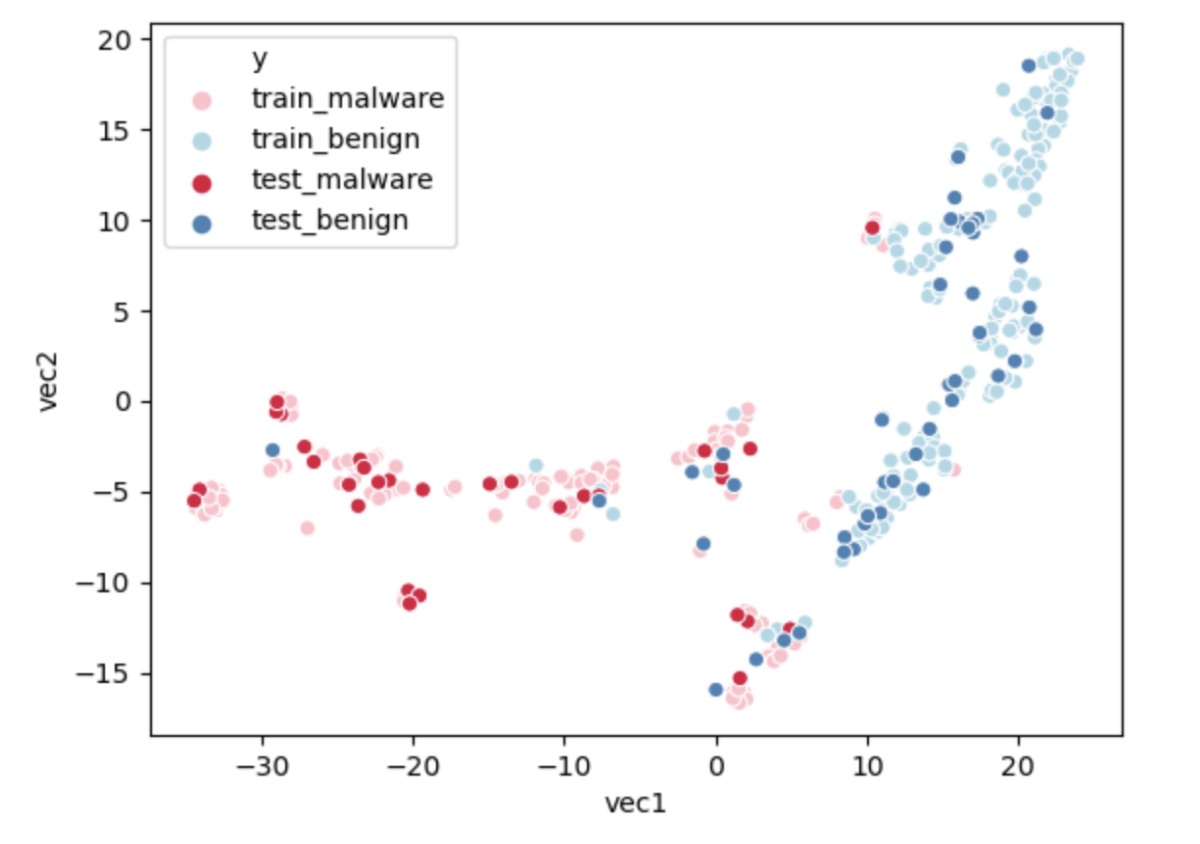
Node2Vec
The only difference between Node2Vec and Word2Vec is the random walk procedure. This change improves the inability of Word2Vec and tracks the path with no specific rules about where to go.
We use all A, B, and P matrices to build our Node2Vec. Since the B and P matrices both represent the relationships between apis, we combine the two matrices into one larger matrix to replace the B and P matrices. The values within the large matrix represent whether two apis have some relationships, no matter whether they are within the same code block or use the same package.
For the probability of random walks, there are three types of probability. For example,from the graph below, we have a path from t -> v. When choosing the next step for v, we have three different probabilities. If we get from v -> t, we have a probability of 1/p. In addition, if the next node from v has a connection with t, then the probability of the node will be 1. Other nodes will have a probability with 1/q. We then implement sentences into the genism’s Node2Vec model. The p value we select in our Node2Vec is 1 and the q value we select is 1/2. We choose a larger p value since we do not want our path going back to its previous node.
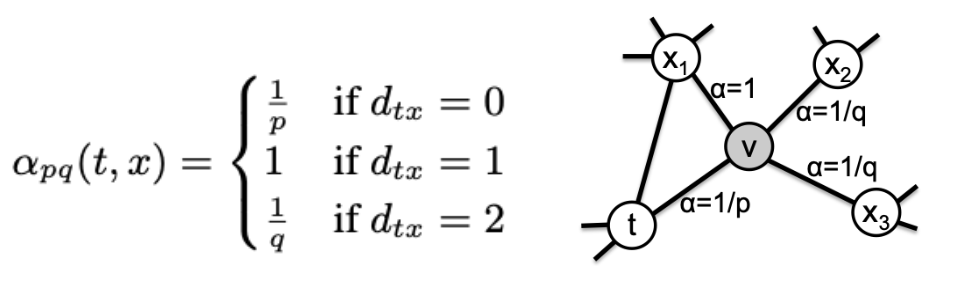
Similar to Word2Vec, we also plot out the vector embeddings after finishing the dimension reduction. The plot we get is shown below:
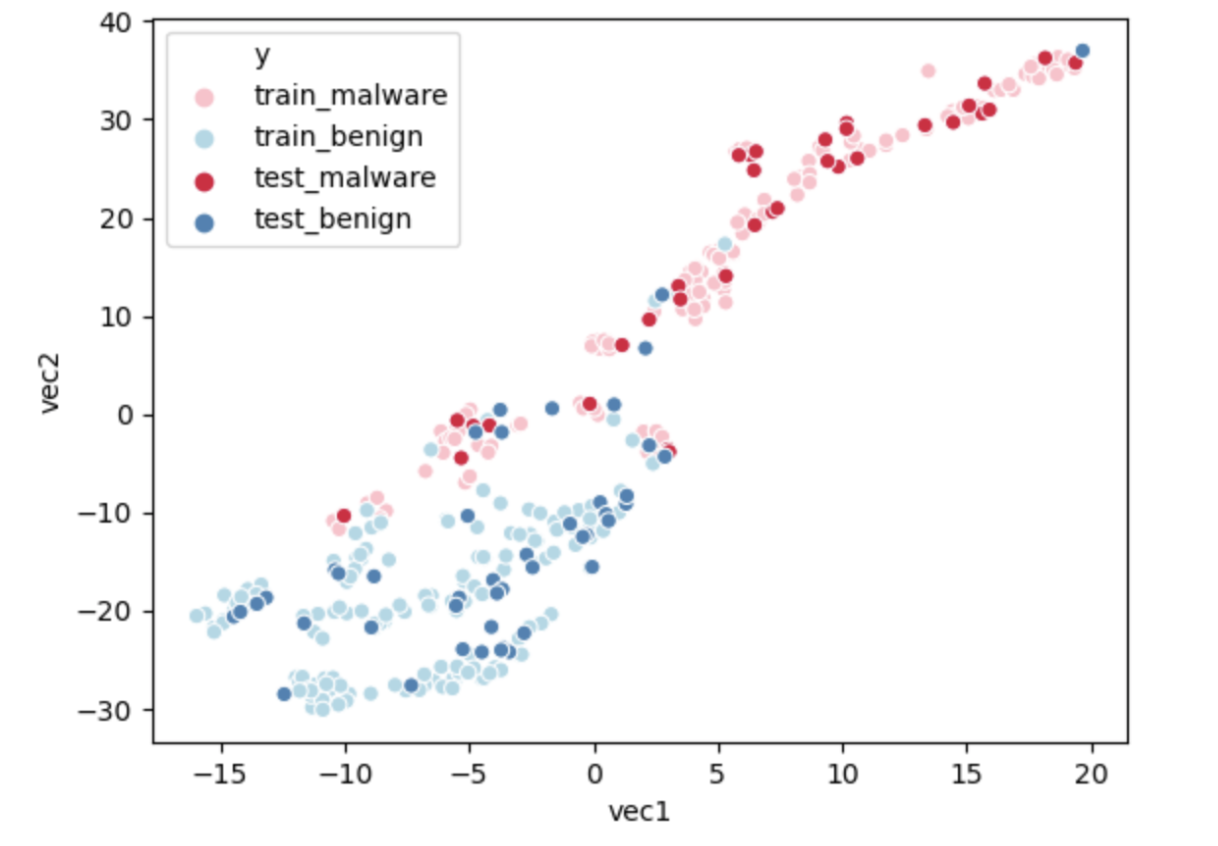
Metapath2Vec
Methpath2Vec is an extension of Node2Vec on heterogeneous graphs. The difference between Metapath2Vec and Node2Vec is that the Metapath2Vec assigns a path for the random walk and decides where the next node to go. The Metapath2Vec model uses all A, B, and P matrices. The sampling method of Metapath2Vec is based on the equation (1), which means the next node will be accessed if the edge exists and the node belongs to the correct type. For example, if the path given is ABA, we will generate a sentence from an app to an api first. Then we will check the next node is an api which is in the same code block with the previous api. Finally, our path will go to another app. We repeat this loop until we reach the maximum length we set or have no next node.
We then implement sentences into the genism’s Word2Vec model. After the dimension reduction process is done, the embedding plot is shown figure below:
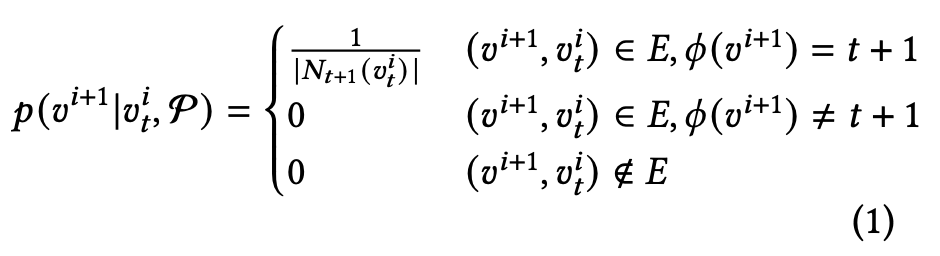
Result
Below are the results of different models.
Classifiers
After different models are built, SVM(Support-Vector Machines), Random Forest, and Gradient Boosting are selected as classifiers while doing the final malware detection. SVM is the baseline classifier we choose. It uses different matrices as custom kernels to classify the type of applications. Random Forest and Gradient Boosting both use decision trees as their base. Decision tree is a tree model in which each node represents a decision rule that separates the dataset. Random forest uses the idea of “Bagging”. It builds lots of decision trees at the same time using a subset from the dataset. Then, Random Forest will combine the result with weight and produce the final prediction. Gradient Boosting uses another idea called “Boosting”. It will also build lots of decision trees. And Gradient Boosting will update the newest model by making improvement on the last model.
The classifier with highest accuracy will be chosen as the classifier of a specific model. As the result table shows, most classifiers will be SVM. However, the Node2vec model shows a preference on Gradient Boosting.
Result Table
As the tables show below, train accuracy, test accuracy, and F1 score are the values to evaluate the performance of the model. We also include False Positive and True Negative count to check which kind of error will the model make. The best performance is the original HinDroid model with AA kernel and SVM classifier, which achieves a test accuracy around 99% with only three benigns misrecognized as malwares.
HinDroid Statistics
| Model | Kernel | Classifier | TrainAcc | TestAcc | F1 | FP | FN |
|---|---|---|---|---|---|---|---|
| HinDroid | AA | SVM | 1 | 0.9917 | 0.9919 | 3 | 0 |
| ABA | Gradient Boosting | 0.9917 | 0.9419 | 0.944 | 13 | 8 | |
| APA | SVM | 1 | 0.9779 | 0.9788 | 8 | 0 | |
| APBPA | Random Forest | 1 | 0.9337 | 0.9358 | 14 | 10 | |
| Reduce API Name | AA | SVM | 1 | 0.9834 | 0.9839 | 5 | 1 |
| ABA | Random Forest | 1 | 0.9419 | 0.9442 | 14 | 7 | |
| Reduce API Pack | AA | SVM | 1 | 0.9889 | 0.9893 | 4 | 0 |
| ABA | Gradient Boosting | 0.9965 | 0.9419 | 0.9415 | 17 | 4 | |
| TF-IDF 1000 | AA | SVM | 1 | 0.9861 | 0.9865 | 2 | 3 |
| AIA | Random Forest | 1 | 0.9143 | 0.916 | 14 | 17 | |
| TF-IDF 2000 | AA | SVM | 1 | 9,917 | 0.9919 | 2 | 1 |
| ABA | Random Forest | 1 | 0.9475 | 0.9493 | 12 | 7 | |
| APA | SVM | 1 | 0.9834 | 0.9839 | 5 | 1 | |
| APBPA | Decision Tree | 1 | 0.9309 | 0.9326 | 13 | 12 | |
| ABPBA | SVM | 1 | 0.9806 | 0.9812 | 5 | 2 | |
| AIA | Random Forest | 1 | 0.9198 | 0.923 | 18 | 11 | |
| ABPIPBA | Gradient Boosting | 0.9261 | 0.9088 | 0.9133 | 22 | 11 | |
| TF-IDF 5000 | AA | SVM | 1 | 0.9889 | 0.9892 | 3 | 1 |
| AIA | Gradient Boosting | 0.9488 | 0.9198 | 0.9238 | 20 | 9 | |
| TF-IDF 10000 | AA | SVM | 1 | 0.989 | 0.9892 | 3 | 1 |
| AIA | Gradient Boosting | 0.9537 | 0.9171 | 0.9215 | 21 | 9 | |
| API Return Type | RR | SVM | 1 | 0.9862 | 0.9867 | 5 | 0 |
| RBR | Gradient Boosting | 0.9896 | 0.9282 | 0.9319 | 19 | 7 |
Graph Statistics
| Model | Metapath | Classifier | TrainAcc | TestAcc | F1 | FP | FN |
|---|---|---|---|---|---|---|---|
| Word2Vec | AA | Gradient Boosting | 0.9993 | 0.9475 | 0.9501 | 15 | 4 |
| Node2Vec | AA | Random Forest | 1 | 0.942 | 0.944 | 13 | 8 |
| All | Gradient Boosting | 0.9965 | 0.9475 | 0.9501 | 15 | 4 | |
| Metapath2Vec | AA | Gradient Boosting | 0.9717 | 0.9448 | 0.9465 | 12 | 8 |
| ABA | Gradient Boosting | 0.9869 | 0.9337 | 0.9371 | 18 | 6 | |
| APA | Gradient Boosting | 0.9931 | 0.9448 | 0.9474 | 15 | 5 |
Research on misclassified applications
After seeing the result, we do some research on the misrecognized applications. As the table shown, the original HinDroid model with metapath AA and classifier SVM only missed 3 applications. Those three applications are considered to be False Positive, which means that they should be benigns but identified as malwares. We select those 3 applications out and find that they are all in the category Random application. By checking the features used for malware detection and comparing it with the 25% - 75% range for both malwares and benigns, those applications are at the boundary of malwares and benigns. Therefore, it is reasonable for the classifier to misrecognizing those applications. In addition, as the Data Description section mentioned, random applications are selected randomly out of apkpure. There is a small possibility that those three applications are actually malwares.
| # of Unique API (Lib + Name) | # of Unique API Name | # of Unique Api Pack | # of Unique Return Types | |
|---|---|---|---|---|
| Missed APP1 | 4064 | 2001 | 1281 | 728 |
| Missed APP2 | 2346 | 1068 | 729 | 429 |
| Missed APP3 | 2270 | 1035 | 683 | 413 |
| Benign | 4062-9851 | 1395-3602 | 1446-3667 | 884-2069 |
| Malware | 96-1224 | 71-174 | 38-433 | 34-276 |
Conclusion
In this report, we implement different methods for malware detection. Based on the weakness we find in using HinDroid, we also design some new matrices and kernels in order to save space and time. As the result section shows, the outcome is positive. With a much smaller matrix and time complexity, the new model can perform as well as the original HinDroid model. Although graph-based models do not perform as well as kernel based models, they are achieving a high accuracy around 95%. Graph is still a useful strategy to consider while detecting malwares since it can catch the cluster relationship among applications.
There is lots of future exploration that can be done based on current results. For example, we can implement the multi-kernel idea to combine high accuracy models together in order to improve our overall accuracy. The reducing API by using TF-IDF can also be applied to other research areas while we want to save time complexity. New matrix with return types as its element also performs well on test accuracy. Thus, some further studies can be done on this feature. We can also extract out most common applications which are misclassified and understand the reason behind it.
Reference
- Hou, Shifu and Ye, Yanfang and Song, Yangqiu and Abdulhayoglu, Melih. 2017. HinDroid: An Intelligent Android Malware Detection System Based on Structured Heterogeneous Information Network.
- Mikolov, Tomas and Corrado, Greg and Chen, Kai and Dean, Jeffrey. 2013. Efficient Estimation of Word Representations in Vector Space.
- Grover, Aditya and Leskovec, Jure. 2016. node2vec: Scalable Feature Learning for Networks.
- Dong, Yuxiao and Chawla, Nitesh and Swami, Ananthram. 2017. metapath2vec: Scalable Representation Learning for Heterogeneous Networks